DeepSeek의 새로운 챗봇은 인상적인 소개를 자랑합니다. "안녕하세요, 나는 당신이 무엇이든 물어보고 당신을 놀라게 할 수있는 답을 얻을 수 있도록 만들어졌습니다." 중국 스타트 업 Deepseek의 제품인이 AI는 빠르게 주요 선수가되어 Nvidia의 주가가 크게 하락하기까지했습니다.
 이미지 : ensigame.com
이미지 : ensigame.comDeepseek의 성공은 혁신적인 건축 및 훈련 방법에서 비롯됩니다. 주요 기술에는 다음이 포함됩니다.
- MTP (Multi-Token Prediction) : 단어를 개별적으로 예측하는 대신 MTP는 여러 단어를 동시에 예측하여 정확도와 효율성을 높입니다.
- 전문가 (MOE)의 혼합 : 이 아키텍처는 DeepSeek V3의 256 개의 신경망을 사용하여 각 토큰 처리 작업마다 8 개를 활성화하고 교육을 가속화하고 성능을 향상시킵니다.
- MLA (Multi-Head Prenatent Attention) : MLA는 텍스트 조각에서 주요 세부 정보를 반복적으로 추출하여 중요한 정보를 놓치지 않도록하여 입력 데이터에 대한 미묘한 이해를 초래합니다.
DeepSeek은 처음에 2048 GPU 만 사용하여 DeepSeek V3의 경우 6 백만 달러의 매우 낮은 교육 비용을 주장했습니다. 그러나 Semianalysis는 훨씬 더 광범위한 인프라를 보여주었습니다. 약 50,000 개의 NVIDIA HOPPER GPU (10,000 H800, 10,000 H100 및 추가 H20 포함)는 여러 데이터 센터에 퍼져 있으며 약 16 억 달러의 총 서버 투자를 대략 9,400 만 달러의 운영 비용을 나타냅니다.
 이미지 : ensigame.com
이미지 : ensigame.com중국 헤지 펀드 High-Flyer의 자회사 인 DeepSeek는 데이터 센터를 소유하여 최적화와 더 빠른 혁신 구현에 대한 제어를 제공합니다. 이 자체 지원 접근법은 유연성과 의사 결정을 향상시킵니다. 이 회사는 최고의 인재를 유치하며 일부 연구자들은 주로 중국 대학에서 매년 130 만 달러 이상을 벌고 있습니다.
 이미지 : ensigame.com
이미지 : ensigame.com6 백만 달러의 교육 비용 청구는 연구, 개선, 데이터 처리 및 인프라를 제외하고 사전 훈련 GPU 사용만을 나타내는 상당한 과소 평가로 보입니다. AI 개발에 대한 DeepSeek의 실제 투자는 5 억 달러를 초과합니다. 그럼에도 불구하고, 린 구조는 더 큰 관료적 회사에 비해 효율적인 혁신을 허용합니다.
 이미지 : ensigame.com
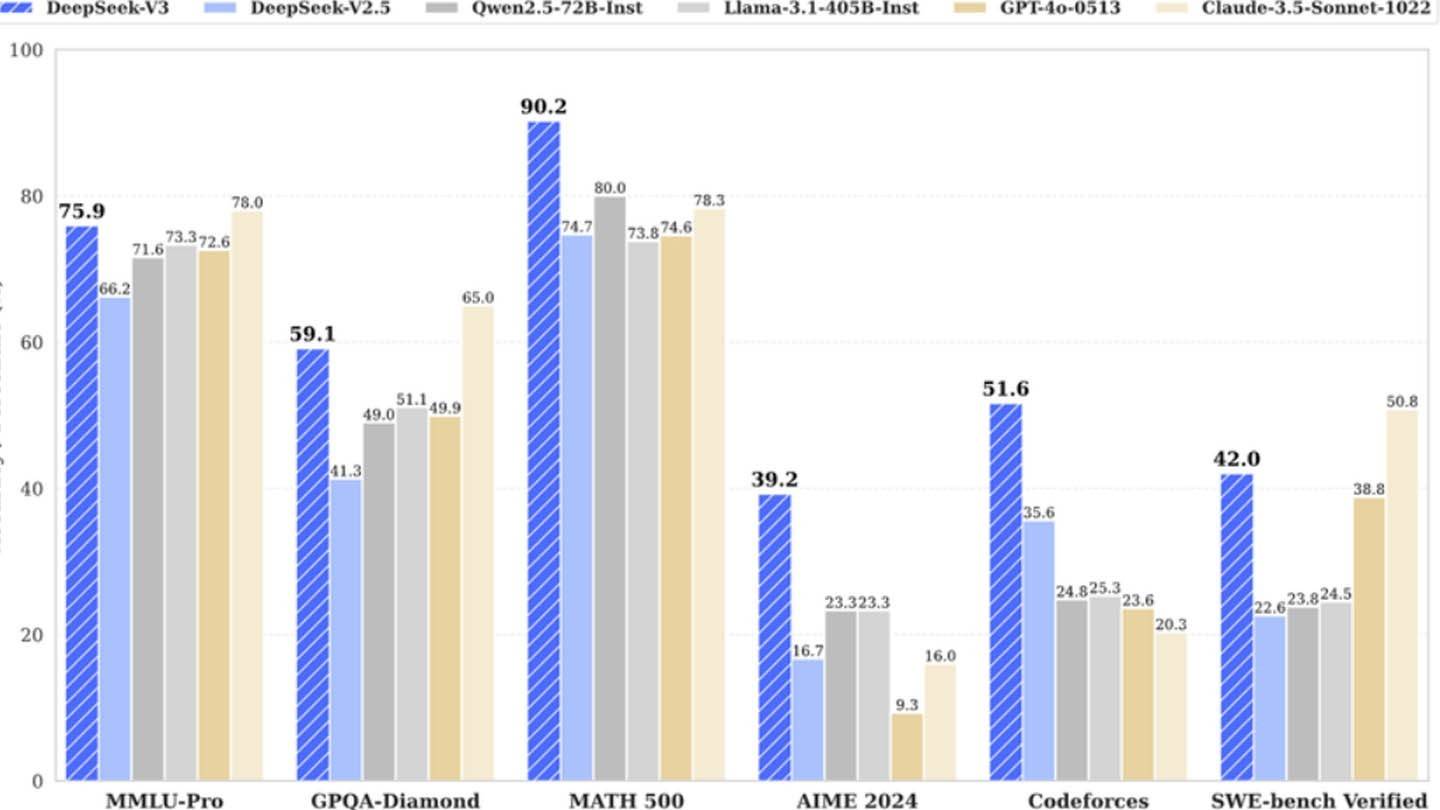
이미지 : ensigame.comDeepSeek의 성공은 잘 자금을 지원하는 독립 AI 회사가 업계 거인과 경쟁 할 수있는 잠재력을 강조합니다. "혁신적인 예산"주장이 과장되지만, 그 성공은 실질적인 투자, 기술 혁신 및 강력한 팀과 관련이 없습니다. 대조는 교육 비용을 비교할 때 엄격합니다. DeepSeek의 R1은 5 백만 달러, ChatGpt-4는 1 억 달러입니다. 그러나 경쟁사보다 여전히 저렴합니다.





![Taffy Tales [v1.07.3a]](https://imgs.xfsxw.com/uploads/32/1719554710667e529623764.jpg)